문제 상황
Stock.class
@Entity
@NoArgsConstructor
@Getter
public class Stock {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private Long productId;
private Long quantity;
public Stock(Long productId, Long quantity) {
this.productId = productId;
this.quantity = quantity;
}
public void decrease(Long quantity) {
if (this.quantity - quantity < 0) {
throw new RuntimeException("재고 수량 부족");
}
this.quantity -= quantity;
}
}StockService
@Service
@RequiredArgsConstructor
public class StockService {
private final StockRepository stockRepository;
@Transactional
public void decrease(Long id, Long quantity) {
Stock stock = stockRepository.findById(id).orElseThrow();
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}
}
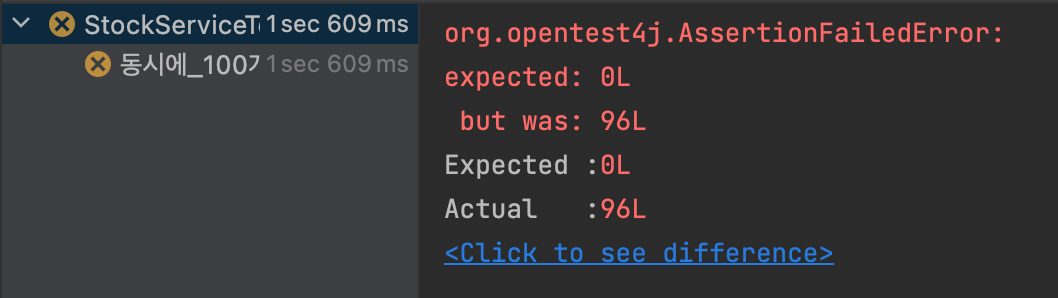
이커머스 서비스를 개발 중 위 코드를 아래와 같이 멀티 쓰레드 환경에서 테스트 했을 때 테스트에 실패했다. productId가 1인 상품을 100개 생성한 뒤 1번 상품을 1개씩 100번 감소 한다고 가정하고 테스트 했을때 남은 수량이 0일 것이라고 예상했지만 결과는 남은 수량이 96개로 예상했던 결과와 다르게 나왔다.
이유는 경쟁 상태(race condition)가 발생했기 때문인데 경쟁 상태란 각 프로세스, 스레드가 동시에 접근할 수 있는 공유 자원(shared resource)에 두 개 이상의 프로세스나 스레드가 동시에 읽거나 쓰는 상황을 말하며 공유 자원 접근 타이밍이나 순서 등이 결과값에 영향을 줄 수 있는 상태를 의미한다.
위 상황을 예로 들면 재고 수량이 100개 인 상태에서 동시에 2개의 스레드가 decrease 메소드를 테스트 하면 2개가 차감되어야 하지만 두 스레드 모두 재고 수량이 100개인 상태에서 접근하여 수량을 1개씩 차감하기 때문에 결과값이 모두 99개로 1개만 차감한 것이 된다. 이런 문제를 동시성 이슈라고 한다.
StockServiceTest
@SpringBootTest
class StockServiceTest {
@Autowired
private StockService stockService;
@Autowired
private StockRepository stockRepository;
@BeforeEach
public void before() {
Stock stock = new Stock(1L, 100L);
stockRepository.saveAndFlush(stock);
}
@AfterEach
public void delete() {
stockRepository.deleteAll();
}
@Test
public void 동시에_100개의_요청() throws InterruptedException {
int threadCount = 100;
// 비동기로 실행하는 작업을 단순화 하여 사용할 수 있게 도와주는 자바의 API
ExecutorService executorService = Executors.newFixedThreadPool(32);
// 다른 스레드에서 수행 중인 작업이 완료될 때까지 대기할 수 있도록 도와주는 클래스
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
stockService.decrease(1L, 1L);
} finally {
latch.countDown();
}
});
}
latch.await();
Stock findStock = stockRepository.findById(1L).orElseThrow();
assertThat(findStock.getQuantity()).isEqualTo(0L);
}
}
강의에서는 동시성 문제를 해결하기 위한 방법으로 synchronized 선언, 데이터베이스를 이용한 락(Pessimistic Lock, Optimistic Lock, Named Lock), redis를 이용한 락(Lettuce Lock, Redisson Lock)을 소개하고 있다.
Synchronized 선언
synchronized는 멀티스레드 환경에서 스레드간 데이터 동기화를 시켜주는 자바에서 제공하는 키워드로 선언 방법은 아래 코드와 같이 문제가 되는 메소드 선언부에 synchronized 선언만 해주면 된다.
@Service
@RequiredArgsConstructor
public class StockService {
private final StockRepository stockRepository;
@Transactional
public synchronized void decrease(Long id, Long quantity) {
Stock stock = stockRepository.findById(id).orElseThrow();
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}
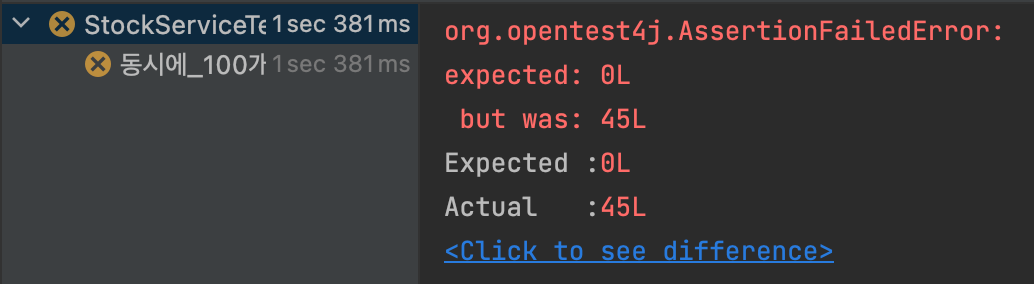
}다시 테스트해보면 synchronized를 선언했음에도 아래와 같이 테스트가 실패한 것을 확인할 수 있다. 이는 decrease() 메소드가 종료된 시점과 트랜잭션이 종료되는 시점 사이에 다른 스레드가 접근하게 되면 이 스레드는 변경사항이 디비에 반영되기 전의 재고 수량을 조회하여 decrease() 메소드를 호출하기 때문에 이와 같은 문제가 발생하는 것이다.
@Transactional 어노테이션을 지우고 테스트 하면 다음과 같이 테스트가 성공하는 것을 확인할 수 있다.

하지만 synchronized는 하나의 프로세스 안에서만 보장이 된다. 즉 서버가 한 대일 때는 decrease() 메소드에 하나의 스레드만 접근하는 것을 보장하지만 서버가 여러대일 때는 synchronized를 선언해도 동시에 여러 스레드가 접근할 수 있기 때문에 문제를 해결할 수 없다.
DB Lock
Pessimistic Lock
실제로 데이터에 락을 걸어서 정합성을 맞추는 방법, exclusive lock을 걸게 되면 다른 트랜잭션에서는 lock이 해제되기 이전에 데이터를 가져갈 수 없다.
- exclusive lock : 쓰기 잠금(write lock)이라고도 불린다. 현재 트랜잭션이 완료될 때까지 다른 트랜잭션에서 lock이 걸린 테이블이나 레코드에 읽거나 쓰지 못한다.
- shared lock : 읽기 잠금(read lock)이라고도 불린다. 읽기는 가능하지만 쓰기는 불가능하다.
장점
- 충돌이 빈번하게 일어난다면 Optimistic Lock 보다 성능이 좋을 수 있다.
- Lock을 통해 update를 제어하기 때문에 데이터 정합성이 어느정도 보장된다.
단점
- 별도의 락을 잡기 때문에 성능 감소가 있을 수 있다.
- 데드락이 걸릴수 있기 때문에 주의해서 사용해야 한다.
데드락이란?
데드락(교착 상태)은 두 개 이상의 프로세스들이 서로가 가진 자원을 기다리며 중단된 상태를 말한다.
사용 방법
Spring Data JPA에서는 아래와 같이 @Lock 어노테이션을 이용해 쉽게 Pessimistic Lock을 구현할 수 있다.
public interface StockRepository extends JpaRepository<Stock, Long> {
@Lock(value = LockModeType.PESSIMISTIC_WRITE)
@Query("select s from Stock s where s.id=:id")
Stock findByIdWithPessimisticLock(@Param("id") Long id);
}위와 같이 메소드를 구현하고 Pessimistic Lock 을 테스트해보기 위해 Service 클래스와 테스트 클래스를 아래와 같이 생성한 후 테스트 해보면 테스트에 성공한 것을 확인할 수 있다.
@Service
@RequiredArgsConstructor
public class PessimisticLockStockService {
private final StockRepository stockRepository;
@Transactional
public void decrease(Long id, Long quantity) {
Stock stock = stockRepository.findByIdWithPessimisticLock(id);
stock.decrease(quantity);
stockRepository.saveAndFlush(stock);
}
}@SpringBootTest
class StockServiceTest {
@Autowired
private PessimisticLockStockService stockService;
...
// 나머지 코드는 맨 위의 테스트 코드와 같습니다.
}
Optimistic Lock
실제로 락을 이용하지 않고 Version을 이용함으로써 정합성을 맞추는 방법, 먼저 데이터를 읽은 후에 update를 수행할 때 현재 내가 읽은 버전이 맞는지 확인하여 update를 한다. 내가 읽은 버전에서 수정사항이 생겼을 경우에는 application에서 다시 읽은 후에 작업을 수행해야 한다.
장점
- 별도의 락을 잡지 않으므로 Pessimistic Lock 보다 성능상의 이점이 있다.
단점
- Update에 실패했을 때를 대비하여 재시도 로직을 개발자가 따로 작성해 주어야 한다.
- 충돌이 빈번하게 일어나는 경우 Pessimistic Lock을 사용하는 것이 더 낫다.
사용 방법
Version을 확인하기 위해 아래와 같이 Stock Entity에 Version 컬럼을 추가하고 @Version 어노테이션을 붙여준다.
@Entity
@NoArgsConstructor
@Getter
public class Stock {
...
@Version
private Long version;
...
}그런 다음 Pessimistic Lock과 마찬가지로 @Lock 어노테이션을 이용해 Optimistic Lock을 이용한 메소드를 구현해주고 이 메소드를 이용해 재고 감소 로직을 작성해준다. 그리고 Optimistic Lock 의 경우 실패했을 때 재시도를 해주어야 하므로 Facade 패턴을 이용해 아래와 같이 실패했을때 50 millisecond 있다가 재시도 해주는 클래스를 생성해 준다.
@Component
@RequiredArgsConstructor
public class OptimisticLockStockFacade {
private final OptimisticLockStockService optimisticLockStockService;
public void decrease(Long id, Long quantity) throws InterruptedException {
while (true) {
try {
optimisticLockStockService.decrease(id, quantity);
break;
} catch (Exception e) {
Thread.sleep(50);
}
}
}
}그리고 나서 아래와 같이 Facade 패턴으로 구현한 Service의 decrease 메소드를 테스트해보면 테스트에 성공한 것을 확인할 수 있다.
@SpringBootTest
class OptimisticLockStockFacadeTest {
@Autowired
private OptimisticLockStockFacade stockService;
...
// 나머지 코드는 맨 위의 테스트 코드와 같습니다.
}
Named Lock
이름을 가진 metadata locking 이다. 이름을 가진 Lock을 획득한 후 해제할 때까지 다른 세션은 이 락을 획득할 수 없다. 주의할 점으로는 transaction이 종료될 때 lock이 자동으로 해제되지 않는다. 그렇기 때문에 별도의 명령어로 해제를 수행해주거나 선점시간이 끝나야 해제된다. Mysql에서는 getLock() 메소드를 통해 Lock을 획득할 수 있고 releaseLock() 메소드를 통해 락을 해제할 수 있다.
사용 방법
테스트 환경에서는 JPA의 Native Query를 활용하고 동일한 DataSource를 활용했지만 실무에서는 DataSource를 분리해서 사용하는 방법을 추천한다. 그 이유는 동일한 DataSource를 사용하게 되면 커넥션 풀이 부족하게 되는 현상이 발생하여 다른 서비스에도 영향을 끼칠 수 있기 때문이다.
먼저 LockRepository를 생성한 후 getLock() 메소드와 releaseLock() 메소드를 작성해 준다.
public interface LockRepository extends JpaRepository<Stock, Long> {
@Query(value = "select get_lock(:key, 3000)", nativeQuery = true)
void getLock(@Param("key") String key);
@Query(value = "select release_lock(:key)", nativeQuery = true)
void releaseLock(@Param("key") String key);
}그런 다음 핵심 로직인 decrease() 메소드 호출 전후로 getLock()과 releaseLock() 메소드를 실행해 주어야 하기 때문에 아래와 같이 Facade 클래스를 생성해준다.
@Component
@RequiredArgsConstructor
public class NamedLockStockFacade {
private final LockRepository lockRepository;
private final StockService stockService;
@Transactional
public void decrease(Long id, Long quantity) {
try {
lockRepository.getLock(id.toString());
stockService.decrease(id, quantity);
} finally {
lockRepository.releaseLock(id.toString());
}
}
}그리고 StockService는 부모의 Transaction과 별도로 실행이 되어야 하기 때문에 StockService의 decrease() 메소드에 작성되어있는 @Transactional 어노테이션에 아래와 같이 propagation 속성을 추가해준다.
public class StockService {
private final StockRepository stockRepository;
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void decrease(Long id, Long quantity) {
...
}
}마지막으로 NamedLockStockFacade 클래스의 decrease() 메소드를 테스트해보면 아래와 같이 성공한 것을 확인할 수 있다.
@SpringBootTest
class NamedLockStockFacadeTest {
@Autowired
private NamedLockStockFacade stockService;
...
// 나머지 코드는 맨 위의 테스트 코드와 같습니다.
}
Redis Lock
Redis를 이용해서 Lock을 걸기 위해서는 먼저 build.gradle에 spring-data-redis 의존성을 추가해준다.
implementation 'org.springframework.boot:spring-boot-starter-data-redis'Lettuce Lock
Lettuce Lock은 setnx 명령어를 활용하여 분산 락을 구현할 수 있다. setnx 명령어는 Key와 Value를 set할때 기존의 값이 없을 때만 set 하는 명령어이다. setnx를 활용하는 방식은 spin-lock 방식이므로 retry 로직을 개발자가 따로 작성해주어야 한다.
spin-lock 방식이란?
Lock을 획득하려는 쓰레드가 Lock을 사용할 수 있는 지 반복적으로 확인하면서 Lock 획득을 시도하는 방식이다.
장점
- 구현이 간단하다.
- spring-data-redis 를 이용하면 기본이 Lettuce 방식을 사용하기 때문에 별도의 라이브러리를 사용하지 않아도 된다.
단점
- spin-lock 방식을 사용하기 때문에 동시에 많은 쓰레드가 Lock을 획득하기 위해 대기 중이라면 Redis가 과부화가 걸릴 수도 있다.
사용 방법
먼저 RedisLockRepository 클래스를 생성한 뒤 Lock을 거는 lock 메소드와 로직이 끝났을때 Lock을 해제하는 unLock 메소드를 작성해 준다.
@Component
@RequiredArgsConstructor
public class RedisLockRepository {
private final RedisTemplate<String, String> redisTemplate;
public Boolean lock(Long key) {
return redisTemplate
.opsForValue()
.setIfAbsent(generateKey(key), "lock", Duration.ofMillis(3_000));
}
public Boolean unLock(Long key) {
return redisTemplate.delete(generateKey(key));
}
private String generateKey(Long key) {
return key.toString();
}
}그런 다음 아래와 같이 Lock을 획득할 수 있을 때까지 RedisLockRepository의 lock 메소드를 반복 실행해주는 Facade 클래스를 생성해 준다.
@Component
@RequiredArgsConstructor
public class LettuceLockStockFacade {
private final RedisLockRepository redisLockRepository;
private final StockService stockService;
@Transactional
public void decrease(Long id, Long quantity) throws InterruptedException {
while (!redisLockRepository.lock(id)) {
Thread.sleep(100);
}
try {
stockService.decrease(id, quantity);
} finally {
redisLockRepository.unLock(id);
}
}
}마지막으로 LettuceLockStockFacade 클래스의 decrease() 메소드를 테스트해주는 테스트 클래스를 작성한 후 테스트해보면 성공한 것을 확인할 수 있다.
@SpringBootTest
class LettuceLockStockFacadeTest {
@Autowired
private LettuceLockStockFacade stockService;
...
// 나머지 코드는 맨 위의 테스트 코드와 같습니다.
}
Redisson Lock
pubsub 기반의 락 구현, redisson의 경우 락 관련된 클래스를 제공해주기 때문에 별도의 Repository를 작성해 주지 않아도 된다.
pubsub 기반이란?
채널을 하나 만들고 Lock을 점유중인 쓰레드가 Lock을 획득하려고 대기 중인 쓰레드에게 해제를 알려주면 안내를 받은 쓰레드가 Lock 획득을 시도를 하는 방식이다.
장점
- 별도의 retry 로직을 작성하지 않아도 된다.
- pub-sub 방식을 사용하기 때문에 Lettuce와 비교했을 때 redis에 부하가 덜 간다.
단점
- 별도의 라이브러리를 사용해야 한다.
- Lock을 라이브러리 차원에서 제공해주기 때문에 사용법을 공부해야 한다.
사용방법
먼저 Redisson 방식을 사용하기 위해서는 아래와 같이 redisson 라이브러리를 추가해주어야 한다.
// https://mvnrepository.com/artifact/org.redisson/redisson-spring-boot-starter
implementation group: 'org.redisson', name: 'redisson-spring-boot-starter', version: '3.19.0'그런 다음 Redisson 방식은 별도의 Repository를 생성해 주지 않아도 되기 때문에 바로 Lock 획득을 시도하고 StockService의 decrease 메소드를 호출해주는 Facade 클래스를 생성해 준 뒤 같은 로직으로 테스트 해보면 성공한 것을 확인할 수 있다.
@Slf4j
@Component
@RequiredArgsConstructor
public class RedissonLockStockFacade {
private final RedissonClient redissonClient;
private final StockService stockService;
@Transactional
public void decrease(Long id, Long quantity) {
RLock lock = redissonClient.getLock(id.toString());
try {
boolean available = lock.tryLock(5, 1, TimeUnit.SECONDS);
if (!available) {
log.info("lock 획득 실패");
return;
}
stockService.decrease(id, quantity);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
lock.unlock();
}
}
}@SpringBootTest
class RedissonLockStockFacadeTest {
@Autowired
private RedissonLockStockFacade stockService;
...
// 나머지 코드는 맨 위의 테스트 코드와 같습니다.
}
DB Lock vs Redis Lock
Mysql
- Mysql을 이미 사용하고 있다면 별도의 비용없이 사용이 가능하다.
- 어느정도의 트래픽까지는 문제없이 활용이 가능하지만 그래도 Redis를 이용한 방식보다는 성능이 좋지 않다.
Redis
- Mysql 방식보다 성능이 뛰어나다.
- Redis를 사용하는 중이 아니었다면 별도의 구축비용과 인프라 관리비용이 발생한다.
'Spring' 카테고리의 다른 글
| [Spring] Interceptor와 ServletFilter의 차이 (0) | 2023.03.07 |
|---|---|
| [Spring] @AuthenticationPrincipal null (0) | 2023.01.12 |
| 리팩토링 (1) | 2022.12.02 |
| [Spring] 스프링 빈 설정 (XML, JAVA, Component Scan) (0) | 2022.11.08 |
| [Spring] Spring Framework, Spring Web MVC (0) | 2022.11.08 |

