객체 지향 프로그래밍이란?
현실 세계에서 어떤 제품을 만들 때 부품을 먼저 개발하고 이 부품들을 하나씩 조립해서 완성된 제품을 만들 듯이 소프트웨어를 개발할 때도 부품에 해당하는 객체를 만들고 이 객체를 하나씩 조립해서 완성된 프로그램을 만드는 기법을 객체 지향 프로그래밍(OOP: Object Oriented Programming)이라고 합니다. 즉 객체 지향 프로그래밍은 프로그래밍에서 필요한 데이터를 추상화시켜 속성과 행위를 가진 객체를 만들고 그 객체들 간의 유기적인 상호작용을 통해 로직을 구성하는 프로그래밍 방법입니다.
객체 지향 프로그래밍의 장점
1. 유지보수성이 좋다.
- 연관된 클래스만 코드를 변경하면 되며 절차지향에 비해 유지보수하기 편리합니다.
2. 재사용성이 좋다.
- 만들어 둔 객체를 다른 곳에서도 쓸 수 있으며 외부에서 만든 객체를 가져다 쓰기도 편리합니다.
3. 협업이 가능하다.
- 절차지향에 비해, 담당 파트를 정하기 편리합니다.
객체 지향 프로그래밍의 특징
추상화(Abstraction)
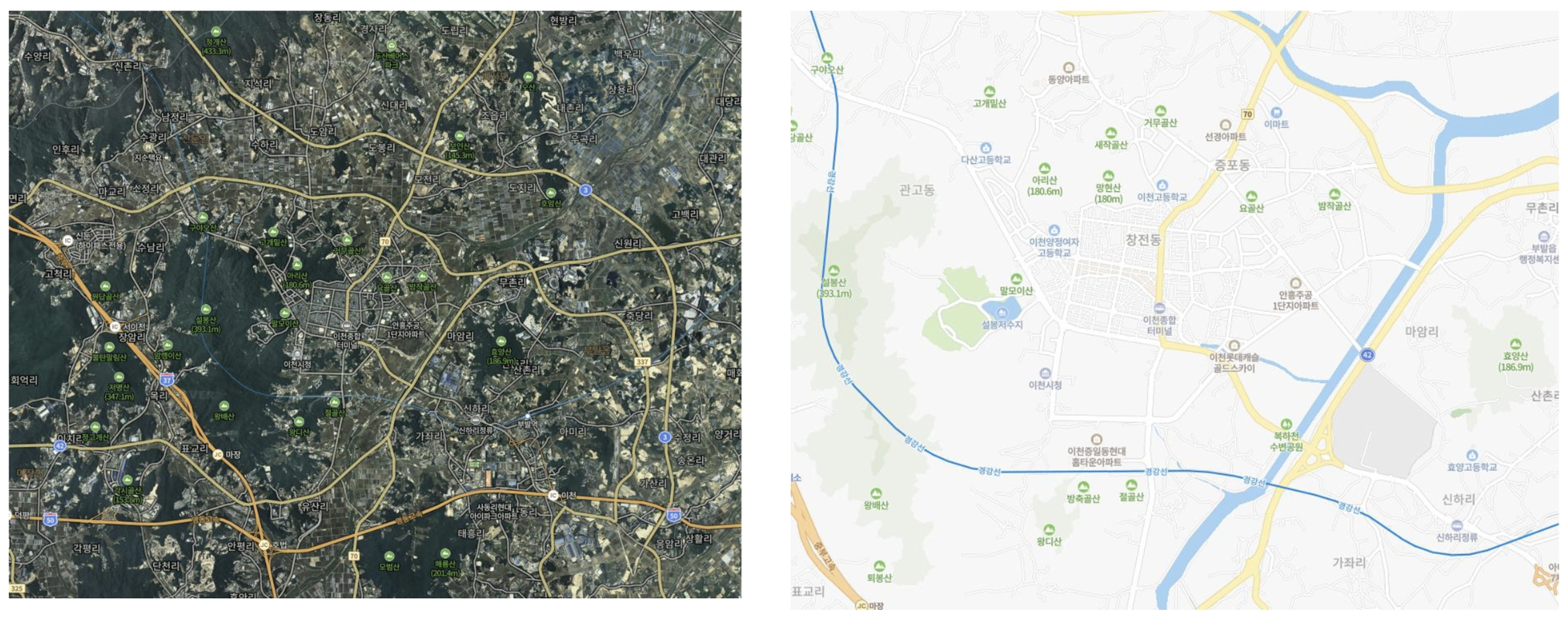
추상화란 복잡한 시스템으로부터 핵심적인 개념 또는 기능을 간추려내는 것을 의미합니다. 예들 들어 위 왼쪽 지도처럼 모든 정보를 표시하는 것이 아닌 오른쪽 지도처럼 필요한 정보들만 간추려서 표현하는 것을 말합니다.
캡슐화(Encapsulation)
캡슐화란 이름에서 알수 있듯이 객체의 필드, 메소드를 하나로 묶고 내용물을 감추는 것을 말합니다. 즉 외부 객체는 호출하고자 하는 객체의 구조는 알지 못하며 객체가 제공하는 필드와 메소드만 이용할 수 있습니다. 캡슐화를 하는 이유는 외부의 잘못으로 필드와 메소드가 손상을 입는 것을 방지하기 위해서 입니다.
상속(Inheritance)
객체 지향 프로그래밍은 부모 역할의 상위 객체와 자식 역할의 하위 객체가 있는데 하위 객체는 상속을 통해서 상위 객체의 필드와 메소드를 사용할수 있습니다. 상속을 사용하면 하위 객체를 쉽고 빠르게 설계할 수 있도록 도와주고 이미 잘 개발된 객체를 상속받아 사용하기 때문에 중복되는 코드를 줄여줍니다. 또한 상위 객체를 수정하면 상위객체를 상속받아 사용하는 하위객체들의 수정 효과도 가져오기 때문에 유지 보수에도 좋습니다.
다형성(Polymorphism)
다형성이란 객체 지향 프로그래밍에서 핵심이 되는 개념으로 컴포넌트를 쉽고 유연하게 변경하면서 개발할 수 있도록 도와줍니다. 즉 같은 타입이지만 실행 결과가 다양한 객체를 이용할 수 있는 성질을 말합니다. 예를 들면 자동차를 설계할 때 타이어 인터페이스 타입을 적용했다면 이 인터페이스를 구현한 실제 타이어들은 어떤 것을 사용하더라도 문제가 되지 않습니다.
다형성의 대표적엔 예로 오버로딩(Overloading)과 오버라이딩(Overriding)이 있습니다.
- 오버로딩(OverLoading) : 클래스 내에 같은 이름의 메소드를 여러 개 선언하는 것을 의미한다. 메소드 오버로딩의 조건은 매개 변수의 타입, 개수, 순서 중 하나가 달라야 한다.
- 오버라이딩(Overriding) : 오버라이딩은 상속에서 등장하는 개념으로 자식 클래스에서 상속받은 부모 클래스의 메소드를 자식 클래스에서 재정의하는 것을 의미한다.
오버로딩의 예
public class Calculator {
// 정사각형의 넓이
double areaRectangle(double width) {
return width * width;
}
// 직사각형의 넓이
double areaRectangle(double width, double height) {
return width * height;
}
}위 코드에서 같은 이름을 가진 메소드를 선언하기 위해 매개변수의 수를 다르게 하여 선언 했습니다. 참고로 리턴 값은 같을 수 있습니다.
오버라이딩의 예
// 부모 클래스
public class Calculator {
public double areaCircle(double r) {
System.out.println("Calculator 객체의 areaCircle() 실행");
return Math.PI * r * r;
}
}// 자식 클래스
public class Computer extends Calculator {
@Override
public double areaCircle(double r) {
System.out.println("Computer 객체의 areaCircle() 실행");
return Math.PI * r * r;
}
}위 코드에서는 부모 클래스인 Calculator 클래스를 자식 클래스인 Computer 클래스가 상속받아 areaCircle 메소드를 재정의하고 있습니다.
오버라이딩에는 다음과 같은 규칙이 있습니다.
- 부모의 메소드와 동일한 시그니처(리턴 타입, 메소드 이름, 매개 변수 리스트)를 가져야 한다.
- 접근 제한을 더 강하게 오버라이딩 할수 없다. ex) 부모(public) -> 자식(default나 private)로 수정 불가
- 새로운 예외처리를 할 수 없다.
예시에서도 리턴 타임과 메소드 이름, 매개 변수 리스트를 동일하게 설정해 주었고 접근 제한자를 public으로 동일하게 설정해 주었습니다.
참고로 자식 클래스의 @Override 메소드는 생략해도 되지만 Override 어노테이션을 선언해주면 컴파일 시점에서 체크를 해주기 때문에 개발자의 실수를 줄여줍니다. 예를 들어 @Override 선언해주었는데 메소드 이름이 틀리면 컴파일 에러가 발생합니다.
설계원칙
객체지향 프로그래밍을 설계할 때는 SOLID 원칙을 지켜주어야 합니다. SOLID 원칙은 각각 단일 책임 원칙(S), 개방-폐쇄 원칙(O), 리스코프 치환 원칙(L), 인터페이스 분리 원칙(I), 의존 역전 원칙(D)을 의미하며 각각의 특징은 아래와 같습니다.
단일 책임 원칙(SRP, Single Responsibility Principle)
- 모든 클래스는 각각 하나의 책임만 가져야 한다.
- 예를 들어 A라는 로직이 존재할때 특정 클래스는 A와 관련된 클래스여야 하고 이를 수정한다고 해도 A와 관련된 수정이어야 한다.
개방-폐쇄 원칙(OCP, Open Closed Principle)
- 유지 보수 시 코드를 쉽게 확장할 수 있도록 하고 수정할 는 닫혀 있어야 한다.
- 즉, 기존의 코드는 변경하지 않으면서도 확장은 쉽게 할 수 있어야 한다.
리스코프 치환 원칙(LSP, Liskov Substitution Principle)
- 프로그램 객체는 프로그램의 정확성을 깨뜨리지 않으면서 하위 타입의 인스턴스로 바꿀 수 있어야 한다.
- 즉, 상속 관계에 있는 부모, 자식 객체가 있을때 부모 객체에 자식 객체를 넣어도 시스템이 문제없이 돌아가게 만드는 것을 의미한다.
인터페이스 분리 원칙(ISP, Interface Segregation Principle)
- 하나의 일반적인 인터페이스보다 구체적인 여러 개의 인터페이스를 만들어야 하는 원칙을 의미한다.
의존 역전 원칙(DIP, Dependency Inversion Principle)
- 추상적인 것은 자신보다 구체적인 것에 의존하지 않고, 변화하기 쉬운 것에 의존해서는 안된다. 즉, 구현 클래스에 의존하지 말고, 인터페이스에 의존해야 하는 원칙을 의미한다.
- 예를 들어 타이어를 갈아끼울 수 있는 틀을 만들어 놓은 후 다양한 타이어를 교체할 수 있어야 한다.
- 상위 계층은 하위 계층의 변화에 대한 구현으로부터 독립되어야 한다.
객체 지향 프로그래밍의 특징과 원칙들을 지키며 코드를 작성하면, 시스템의 유지보수성과 확장성이 높아져 프로젝트가 성장하면서 발생하는 다양한 요구 변화에 유연하게 대응할 수 있습니다.
'Java' 카테고리의 다른 글
| [Java] 인터페이스란 무엇인가? (0) | 2024.10.30 |
|---|---|
| [Java] 추상 클래스란 무엇인가? (0) | 2024.10.30 |
| [Java] 자바 가상 머신(JVM)란 무엇인가? (2) | 2024.10.29 |
| [Java] 이것이 자바다 - 상속 (1) | 2023.07.04 |
| [Java] 인접행렬, 인접리스트 (0) | 2023.02.28 |